
I am writing a series of AI focussed articles to inform and create debate around this world changing subject that’s become a bit of an obsession of mine in recent times.
I’m seeking opportunities to advise companies on AI strategy in a formal capacity, or an informal route if you are just interested to engage on all things AI – just drop me a line!
What is AI?
AI has its roots in the mid-20th century, with esteemed visionaries, Alan Turing and John McCarthy. However, it hardly set the world alight at the time and failed optimism led to the “AI Winter” in the 1970s and 80s where the conceptual expectation far exceeded existing computational capabilities.
Post-millennium supercomputing and the ability to analyse Big Data saw AI reemerge as a powerful tool for forecasting and prediction techniques. Today, AI is both ubiquitous and widely misunderstood at the same time.
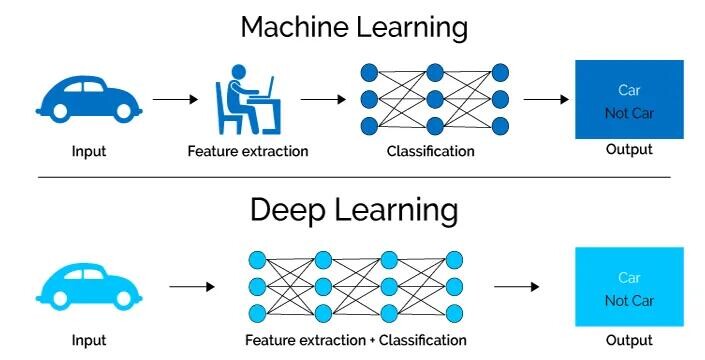
AI is defined as “the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings”. AI is underpinned by 2 forms of Machine Learning (ML) techniques – Traditional Machine Learning and Deep Learning. How can we differentiate between them? I’ll attempt to explain below with some examples:
Machine Learning is akin to teaching a computer to solve puzzles using known techniques, while Deep Learning is like giving the computer the ability to learn how to solve new, more complex puzzles on its own.
Machine Learning is like learning to recognize different types of fruit by their features, whereas Deep Learning is about teaching the computer to not just recognize fruit but also to create recipes based on their flavours and textures.
Machine Learning involves showing a computer many examples to help it learn a task, like sorting coloured blocks, while Deep Learning involves teaching the computer to not only sort the blocks but also to understand and organise them into patterns and structures.
Machine Learning
Pros – Easier to implement and understand, requires less computational power, and works well with smaller datasets.
Cons – Less capable of handling very complex tasks and requires more guidance in learning from data.
Deep Learning
Pros – Can handle and interpret highly complex data, learns features directly from data without needing manual extraction, and often achieves higher accuracy.
Cons – Requires large amounts of data and significant computational power, and is often seen as a ‘black box’ due to its complexity.
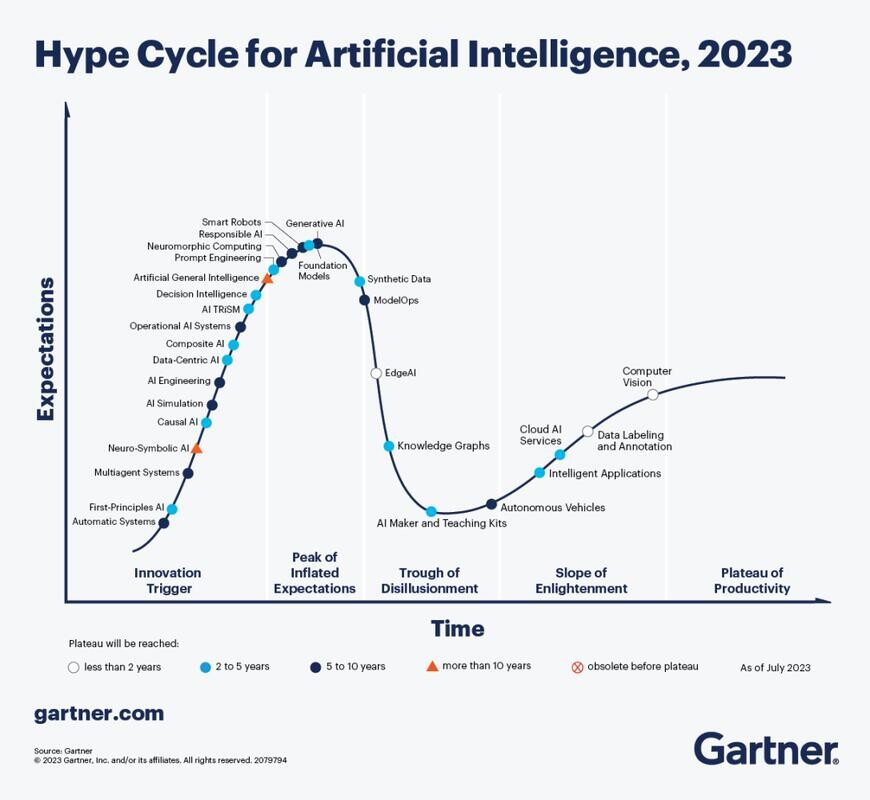
It’s important to know where we are chronologically in this AI journey and how mature AI is as a technology.The best way to visualise this is to apply Gartner’s Hype Curve model. Gartner is a US consultancy firm conducting expert technology research and their Hype Curve is a very popular tool for technology development that shows key stages of development that most innovation experiences on its perilous journey to maturity:
- Innovation Trigger: Initial tech breakthrough. Early PoC stories and media interest trigger significant publicity. Often no MVP or commercial viability is unproven
- Peak of Inflated Expectations: Early publicity creates successes — and failures.
- Trough of Disillusionment: Interest wanes as experiments and implementations fail to deliver. Tech producers shake out or fail. Investments continue only if the surviving providers improve their products to the satisfaction of early adopters
- Slope of Enlightenment: Technology matures along with a volume of users gaining a true understanding of the technology and its best commercial use cases. Second- and third-generation products appear from technology providers. More enterprises fund pilots; conservative companies remain cautious
- Plateau of Productivity: Mainstream adoption, understanding and recognition occurs. Criteria for assessing provider viability are more clearly defined. The technology’s broad market applicability and relevance are clearly paying off
AI’s Exponential growth
AI is so mainstream now, we take it for granted, yet it would have been ‘witchcraft’ only 20 years ago! Where’s the sudden growth come from? Around 12 years ago the use of GPUs to do the heavy lifting in ML computation made a significant breakthrough with many in the AI research community realising GPU architecture was more capable than CPUs.
In 2012, a team led by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton made a breakthrough in the ImageNet competition, a large visual recognition challenge. Their deep neural network, named “AlexNet”, significantly outperformed the competition and was attributed to the use of GPUs, accelerating the training of their deep learning models.
Commercially, the likes of NVIDIA capitalised on this breakthrough, developing more powerful chips to exploit AI development demand. NVIDIA’s 10-year stock value growth of almost 13,500% shows the incredible success of GPU advances. With much of that growth coming in the last few years, it’s showing no sign of slowing either.
I follow numerous podcasts on AI. One of those is the NVIDIA podcast you can find HERE, which gives valuable insights, away from much of the YouTube hyperbole. The team covers AI development at the coalface of actual commercial solutions and all the associated struggles encountered. I will cover more about the juxtapose of hype and realism in further posts.
In late 2022, an open letter penned by world leaders in AI and ethicists, including Elon Musk and Sam Altman, of OpenAI, urged a pause in AI development, stressing potentially existential risks from rapid, unchecked AI progress. The letter proposed a six-month halt on systems surpassing GPT-4’s capabilities – which is still the benchmark AI tool in early 2024. The 6-month hiatus sought to invoke discussions on ethical, safety standards in AI and highlight the AI community’s concerns about rapid advancements.
The fact that people who stand to gain from AI development should take such a measure was as newsworthy as the letter itself, and piqued the interest of the world at large.
This was followed by a strengthening tide of breakthroughs with numerous Large Language Models (LLM) vying for prominence. This is now pretty much on a weekly basis with new performance metrics being reported to show how LLMs are performing against standardised tests. These tests can be specific to the specialism of the LLM, but are already exceeding the once seeming “holy grail”, Turing Test, where it’s deemed a user cannot determine if they are interacting with a computer or not.
Three popular tests used to evaluate the performance of LLMs:
Winograd Schema Challenge: This test assesses the model’s understanding of language context and nuance through questions that require common sense reasoning.
SuperGLUE Benchmark: An advanced version of the GLUE benchmark, offering more challenging tasks pushing the limits of LLMs in understanding complex language scenarios.
SQuAD (Stanford Question Answering Dataset): Focused on reading comprehension, this benchmark tests a model’s ability to answer questions based on given text passages, evaluating its information extraction and synthesis skills.
The State of the Art
As of publishing this post in January 2024, most of us will be familiar with at least one AI tool that we use to generate responses from. The ubiquitous one being ChatGPT 3.5 from OpenAI.com. If you have not done so already, I really recommend creating an account with OpenAI for ChatGPT 3.5 HERE and having a go at anything you like, you cannot break it!
Others AI LLMs include:
- GPT-4 by OpenAI – A paid version of 3.5 with more sophisticated results
- PaLM 2 by Google – Competing with Open AI offerings
- Llama 2 by Meta – An open Source LLM
- Claude 2 by Anthropic – Huge capacity for text analysis
So what is an LLM? A Large Language Model is an advanced type of AI model designed to understand, interpret, generate, and respond to human language via Natural Language Processing (NLP). These models are based on deep learning techniques, particularly neural networks, and are trained on vast datasets comprising text from a wide range of sources.
Key characteristics of LLMs include:
- Size: LLMs are ‘large’ both in terms of the amount of data they are trained on and their neural network architecture
- Language Understanding and Generation: They can comprehend text inputs, generate coherent and contextually relevant text outputs, perform translations, answer questions, summarise content, and more
- Training: LLMs are trained using a method called unsupervised learning, where they learn to predict the next word in a sentence given the previous words, without explicit guidance or labelling
- Applications: They are used in a variety of current applications such as chatbots, content creation, translation services, researchers, fraud detection, healthcare diagnostics, financial trading, and software developers
OpenAI recently launched their GPT Store. This is similar concept to Apple’s App Store where you can download GPTs that have been developed by private individuals and companies. The GPTs available on the store are free to use at the time of writing. The intention is to promote the flexible and capable nature of custom AI applications and to provide increased value from the OpenAI ChatGPT 4 subscription model.
To infinity and beyond?
Not quite… yet! Let’s have a dose of reality before we set out to conquer new galaxies.
LLMs are far from perfect. ‘Hallucination’ is a term used when AI invents ‘facts’. For example, an AI might ‘hallucinate’ details in a historical event, combining true and false elements in a convincing manner. My term for this is “Confidently Wrong”. This occurs because AI lacks a true understanding of correctness and bases its responses on what it has been trained on, regardless of the actual truth or accuracy.
LLMs generate responses by statistically predicting the next word based on context from extensive text data held within their model. They iteratively construct sentences, maintaining coherence and relevance. LLMs apply learned grammar and syntax to link multiple clauses or ideas, reflecting the complex structures encountered in their training prior to the release of the LLM. This process enables them to form coherent, contextually appropriate responses, including sentences with multiple interconnected parts.
AI does not “think” or “understand” in the human sense. It processes input based on statistical correlations. Its ‘understanding’ is limited to recognizing patterns seen during training, leading to inaccuracies when users accept results at face value.
AI can inherit and even amplify biases present in its training data, leading to outputs that may be unfair or biassed. This is a significant concern in most applications, but especially where there’s litigation or health risks, law enforcement and healthcare environments.
Understanding these limitations and inaccuracies is vital. It informs how we should use AI responsibly, being wary of its current limitations, especially in critical decision-making scenarios. As AI continues to evolve, addressing these challenges remains a key focus of research and development in the field.
What’s next in my AI series?

Now i’ve covered the basics of AI with this introductory article, my series will cover numerous fast moving and often fiercely debated subjects. I’ll attempt to demystify and pragmatically draw a line somewhere between the hype and what we may expect in a realistic timeframe.
I’ll also assess this thrilling and equally scary tech to cover what it can ‘do for’ and ‘do to’ your company, and how I predict it will change the everyday lives of people globally in the short, medium and longer term.
Subjects will include:
- Convergence of Technologies – How AI power will exponentially accelerate
- Tech & Politics – The biggest players are vying for the AI crown, but it’s not simple or clear how or when that will happen. Here’s the latest details
- Get the Most from AI – AI techniques and best practices
- AI and the Future of Employment – How we must embrace AI and exploit it rather than be adversely impacted
- AI Governance, Privacy, IP & Ethics – It’s dry, but also very important!
- Hyperbole vs Reality – Drawing a pragmatic line between the Sci-Fi and Reality
- Beyond Screens – Robots, Internet of Things (IoT) and Human Machine Interfaces – maybe the greatest impact AI will have?
- Energy and Efficiency – AI is NOT efficient and global resources cannot cope!
- Social Impact – How will society cope with the change and how do we prepare?
- Education – Could AI could completely upend education forever?
- Transport – Self driving coming or the end of private car ownership?
- Sustainability – Can AI save our world?
- Agriculture – Land is a finite resource. How can AI optimise farming?
- Defence – Will the next wars be over data?
- The Future and AGI– will we achieve this state, and what does that mean for mankind?
Due to the pace of AI development, the articles I publish on LinkedIn will be organic and I’m keen to hear what people want to hear next, so if you have any ideas or requests to cover, drop me a line.